本文共 10762 字,大约阅读时间需要 35 分钟。
初识SpringWebFlux
Spring WebFlux是Spring Framework 5.0中引入的新的响应式Web框架。 与Spring MVC不同,它不需要Servlet API,完全异步和非阻塞, 并通过Reactor项目实现Reactive Streams规范,所以性能更高。 并且可以在诸如Netty,Undertow和Servlet 3.1+容器的服务器上运行。
Spring WebFlux特性:
-
异步非阻塞:
众所周知,SpringMVC是同步阻塞的IO模型,资源浪费相对来说比较严重,当我们在处理一个比较耗时的任务时,例如:上传一个比较大的文件,首先,服务器的线程一直在等待接收文件,在这期间它就像个傻子一样等在那,什么都干不了,好不容易等到文件来了并且接收完毕,我们又要将文件写入磁盘,在这写入的过程中,这根线程又再次懵bi了,又要等到文件写完才能去干其它的事情。这一前一后的等待,不浪费资源么?
没错,Spring WebFlux就是来解决这问题的,Spring WebFlux可以做到异步非阻塞。还是上面那上传文件的例子,Spring WebFlux是这样做的:线程发现文件还没准备好,就先去做其它事情,当文件准备好之后,通知这根线程来处理,当接收完毕写入磁盘的时候(根据具体情况选择是否做异步非阻塞),写入完毕后通知这根线程再来处理(异步非阻塞情况下)。相对SpringMVC而言,可以节省系统资源以及支持更高的并发量。
-
响应式(reactive)函数编程:
Spring WebFlux支持函数式编程,得益于对于reactive-stream的支持(通过reactor框架来实现的)
- 不再拘束于Servlet容器:
以前,我们的应用都运行于Servlet容器之中,例如我们大家最为熟悉的Tomcat, Jetty...等等。而现在Spring WebFlux不仅能运行于传统的Servlet容器中(前提是容器要支持Servlet3.1,因为非阻塞IO是使用了Servlet3.1的特性),还能运行在支持NIO的Netty和Undertow中。
Spring WebFlux与Spring MVC的对比图:

Spring WebFlux支持两种编程方式:

异步servlet
在学习webflux之前,我们首先要学习一下异步的servlet。我们需要了解同步servlet阻塞了什么?为什么需要异步servlet?异步servlet能支持高吞吐量的原理是什么?
servlet容器(如tomcat)里面,每处理一个请求会占用一个线程,同步servlet里面,业务代码处理多久,servlet容器的线程就会等(阻塞)多久,而servlet容器的线程是由上限的,当请求多了的时候servlet容器线程就会全部用完,就无法再处理请求(这个时候请求可能排队也可能丢弃,得看如何配置),就会限制了应用的吞吐量!
而异步serlvet里面,servlet容器的线程不会傻等业务代码处理完毕,而是直接返回(继续处理其他请求),给业务代码一个回调函数(asyncContext.complete()),业务代码处理完了再通知我!这样就可以使用少量的线程处理更加高的请求,从而实现高吞吐量!
我们来看一个同步Servlet的示例代码:
package org.example.servlet;import javax.servlet.ServletException;import javax.servlet.annotation.WebServlet;import javax.servlet.http.HttpServlet;import javax.servlet.http.HttpServletRequest;import javax.servlet.http.HttpServletResponse;import java.io.IOException;import java.util.concurrent.TimeUnit;/** * @program: servlet-demo * @description: 同步的Servlet Demo * @author: 01 * @create: 2018-10-04 17:02 **/@WebServlet("/SyncServlet")public class SyncServlet extends HttpServlet { @Override protected void doGet(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException { long timeMillis = System.currentTimeMillis(); // 执行业务代码 doSometing(req, resp); System.out.println("sync use: " + (System.currentTimeMillis() - timeMillis)); } private void doSometing(HttpServletRequest req, HttpServletResponse resp) throws IOException { // 模拟耗时操作 try { TimeUnit.SECONDS.sleep(5); } catch (InterruptedException e) { e.printStackTrace(); } resp.getWriter().append("done"); }} 运行结果如下:
sync use: 5000
从运行结果可以看到,业务代码花了5 秒,但servlet容器的线程几乎没有任何耗时。而如果是同步servlet的,线程就会傻等5秒,这5秒内这个线程只处理了这一个请求。
然后我们来看一下异步Servlet的示例代码:
package org.example.servlet;import javax.servlet.AsyncContext;import javax.servlet.ServletException;import javax.servlet.ServletRequest;import javax.servlet.ServletResponse;import javax.servlet.annotation.WebServlet;import javax.servlet.http.HttpServlet;import javax.servlet.http.HttpServletRequest;import javax.servlet.http.HttpServletResponse;import java.io.IOException;import java.util.concurrent.CompletableFuture;import java.util.concurrent.TimeUnit;/** * @program: servlet-demo * @description: 异步的Servlet Demo * @author: 01 * @create: 2018-10-04 17:16 **/@WebServlet(asyncSupported = true, urlPatterns = "/AsyncServlet")public class AsyncServlet extends HttpServlet { @Override protected void doGet(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException { long timeMillis = System.currentTimeMillis(); // 1.开启异步上下文 AsyncContext asyncContext = req.startAsync(); // 2.异步执行业务代码,放到另一个线程去处理 CompletableFuture.runAsync(() -> doSometing(asyncContext, asyncContext.getRequest(), asyncContext.getResponse())); System.out.println("async use: " + (System.currentTimeMillis() - timeMillis)); } private void doSometing(AsyncContext asyncContext, ServletRequest req, ServletResponse resp) { // 模拟耗时操作 try { TimeUnit.SECONDS.sleep(5); resp.getWriter().append("done"); } catch (InterruptedException | IOException e) { e.printStackTrace(); } // 3.业务代码处理完毕,通知请求结束 asyncContext.complete(); }} 运行结果如下:
async use: 8
可以看到,异步的Servlet不会阻塞Tomcat的线程,异步Servlet可以把耗时的操作交给另一个线程去处理,从而使得Tomcat的线程能够继续接收下一个请求。这就是异步Servlet的工作方式,得益于非阻塞的特性,能够大大提高服务器的吞吐量。
Webflux开发
了解了同步的Servlet和异步Servlet之间的区别以及异步Servlet的工作方式之后,我们就可以开始尝试使用一下Spring的webflux了。
创建一个Spring Boot工程,选择如下依赖:

关于reactor:
spring webflux是基于reactor来实现响应式的。那么reactor是什么呢?我是这样理解的 reactor = jdk8的stream + jdk9的flow响应式流。理解了这句话,reactor就很容易掌握。reactor里面Flux和Mono就是stream,它的最终操作就是 subscribe/block 2种。
Reactor中的Mono和Flux:
Flux 和 Mono 是 Reactor 中的两个基本概念。Flux 表示的是包含 0 到 N 个元素的异步序列。 在该序列中可以包含三种不同类型的消息通知:正常的包含元素的消息、序列结束的消息和序列出错的消息。 当消息通知产生时,订阅者中对应的方法 onNext(), onComplete()和 onError()会被调用。Mono 表示的是包含 0 或者 1 个元素的异步序列。 该序列中同样可以包含与 Flux 相同的三种类型的消息通知。Flux 和 Mono 之间可以进行转换。 对一个 Flux 序列进行计数操作,得到的结果是一个 Mono对象。把两个 Mono 序列合并在一起,得到的是一个 Flux 对象。
我们来看一段代码,理解一下reactor的概念:
package org.example.spring.webflux;import org.reactivestreams.Subscriber;import org.reactivestreams.Subscription;import reactor.core.publisher.Flux;/** * @program: webflux * @description: Reactor Demo * @author: 01 * @create: 2018-10-04 17:58 **/public class ReactorDemo { public static void main(String[] args) { // Mono 0-1个元素 // Flux 0-N 个元素 String[] strings = {"1", "2", "3"}; // 定义订阅者 Subscriber subscriber = new Subscriber<>() { private Subscription subscription; @Override public void onSubscribe(Subscription subscription) { // 保存订阅关系, 需要用它来给发布者响应 this.subscription = subscription; // 请求一个数据 this.subscription.request(1); } @Override public void onNext(Integer item) { // 接受到一个数据, 处理 System.out.println("接受到数据: " + item); // 处理完调用request再请求一个数据 this.subscription.request(1); // 或者 已经达到了目标, 调用cancel告诉发布者不再接受数据了 // this.subscription.cancel(); } @Override public void onError(Throwable throwable) { // 出现了异常(例如处理数据的时候产生了异常) throwable.printStackTrace(); // 我们可以告诉发布者, 后面不接受数据了 this.subscription.cancel(); } @Override public void onComplete() { // 全部数据处理完了(发布者关闭了) System.out.println("处理完了!"); } }; // reactor = jdk8 stream + jdk9 reactive stream // 这里就是jdk8的stream Flux.fromArray(strings).map(Integer::parseInt) // 最终操作,这里就是jdk9的reactive stream .subscribe(subscriber); }} 在以上例子中,我们可以像JDK9那样实现订阅者,并且直接就可以用在reactor的subscribe方法上。调用了subscribe方法就相当于调用了stream的最终操作。有了 reactor = jdk8 stream + jdk9 reactive stream 概念后,在掌握了jdk8的stream和jkd9的flow之后,reactor也不难掌握。
如果对 jdk8 stream 和 jdk9 reactive stream不了解的话,可以参考我另外两篇文章:
了解了reactor的概念后,我们来编写一段测试代码,对比一下webflux的两种开发方式:
package org.example.spring.webflux.controller;import lombok.extern.slf4j.Slf4j;import org.springframework.web.bind.annotation.GetMapping;import org.springframework.web.bind.annotation.RestController;import reactor.core.publisher.Mono;import java.util.concurrent.TimeUnit;/** * @program: webflux * @description: webflux demo * @author: 01 * @create: 2018-10-04 17:47 **/@Slf4j@RestControllerpublic class TestController { /** * 传统的 spring mvc 开发方式 */ @GetMapping("/mvc") public String mvc() { long timeMillis = System.currentTimeMillis(); log.info("mvc() start"); String result = createStr(); log.info("mvc() end use time {}/ms", System.currentTimeMillis() - timeMillis); return result; } /** * spring webflux 的开发方式 */ @GetMapping("/webflux") public Mono webflux() { long timeMillis = System.currentTimeMillis(); log.info("webflux() start"); Mono result = Mono.fromSupplier(this::createStr); log.info("webflux() end use time {}/ms", System.currentTimeMillis() - timeMillis); return result; } private String createStr() { // 模拟耗时操作 try { TimeUnit.SECONDS.sleep(5); } catch (InterruptedException e) { e.printStackTrace(); } return "some string"; }} 访问/mvc,控制台输出日志如下:

访问/webflux,控制台输出日志如下:

以上的例子中,只演示了reactor 里的mono操作,返回了0-1个元素。以下示例则简单演示了flux操作,返回0-N个元素,代码如下:
/** * 使用flux,像流一样返回0-N个元素 */@GetMapping(value = "/flux", produces = MediaType.TEXT_EVENT_STREAM_VALUE)public Fluxflux() { long timeMillis = System.currentTimeMillis(); log.info("webflux() start"); Flux result = Flux.fromStream(IntStream.range(1, 5).mapToObj(i -> { try { TimeUnit.SECONDS.sleep(1); } catch (InterruptedException e) { e.printStackTrace(); } return "flux data--" + i; })); log.info("webflux() end use time {}/ms", System.currentTimeMillis() - timeMillis); return result;}
访问/flux接口后,控制台输出日志如下:

在浏览器上会每隔一秒接收一行数据:
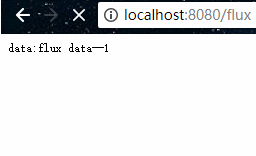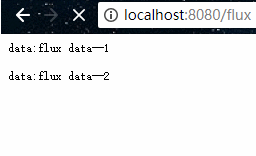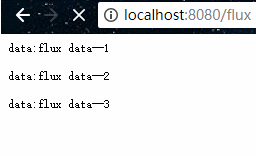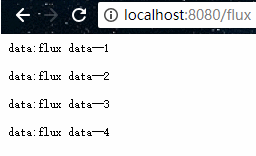
SSE(Server-Sent Events)
在上一小节的例子中我们使用flux返回数据时,可以多次返回数据(其实和响应式没有关系),实际上使用的技术就是H5的SSE。我们学习一个技术,API的使用只是最初级也是最简单的,更加重要的是需要知其然并知其所以然,否则就只能死记硬背不用就忘!我们不满足在spring里面能实现sse效果,更加需要知道spring是如何做到的。
其实SSE很简单,我们花一点点时间就可以掌握,我们在纯servlet环境里面实现。如下示例:
package org.example.servlet;import javax.servlet.ServletException;import javax.servlet.annotation.WebServlet;import javax.servlet.http.HttpServlet;import javax.servlet.http.HttpServletRequest;import javax.servlet.http.HttpServletResponse;import java.io.IOException;import java.util.concurrent.TimeUnit;/** * @program: servlet-demo * @description: SSE Demo * @author: 01 * @create: 2018-10-04 19:37 **/@WebServlet("/ServerSentEventsServlet")public class ServerSentEventsServlet extends HttpServlet { @Override protected void doGet(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException { // 设置返回的数据类型及字符编码 resp.setContentType("text/event-stream"); resp.setCharacterEncoding("UTF-8"); for (int i = 0; i < 5; i++) { // 自定义事件标识(非必须) resp.getWriter().write("event:me\n"); // 需特定格式:data: + 数据 + 2个回车符 resp.getWriter().write("data:" + i + "\n\n"); resp.getWriter().flush(); try { TimeUnit.SECONDS.sleep(1); } catch (InterruptedException e) { e.printStackTrace(); } } }} 其中最为关键的是 ContentType 需为 "text/event-stream",然后返回的数据符合固定的要求格式即可。
使用浏览器访问如下:
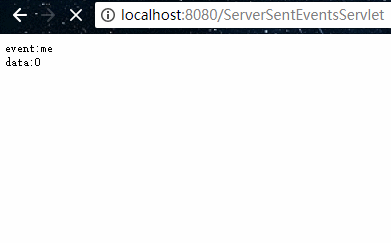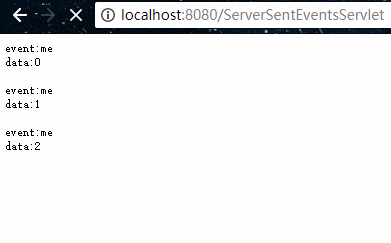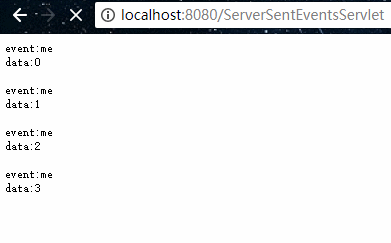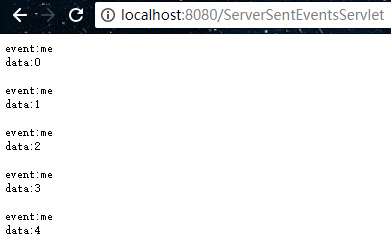
如果前端需要进行一些处理的话,我们也可以编写js代码来获取数据,如下示例:
由于篇幅所限,文中只结合了部分示例介绍了主要的理论知识,所以我另外使用webflux开发了CRUD完整示例demo(非RouterFunction模式),GitHub地址如下:
RouterFunction模式的CRUD完整示例demo,GitHub地址如下:
转载于:https://blog.51cto.com/zero01/2293853